

TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document
TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document

TextMonkey is a large multimodal model(LMM) tailored for text-centric tasks such as document question answering and scenario text analysis.
Overview
TextMonkey enables the enhancement of resolution with limited training resources while preserving cross-window information and reducing redundant tokens introduced by resolution enhancement. Besides, through various data and pretext prompts, TextMonkey has been equipped with the ability to handle multiple tasks.
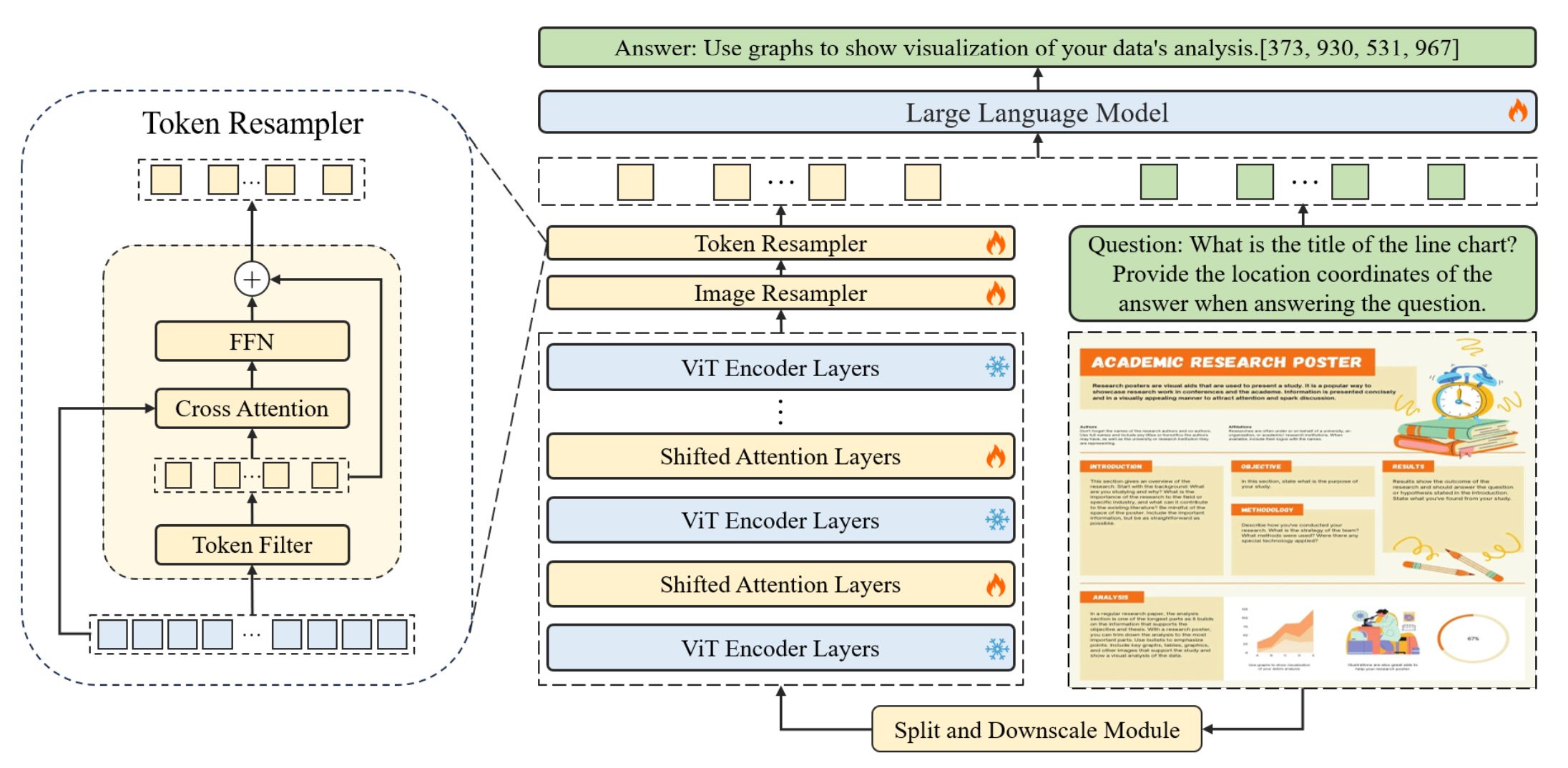
As illustrated in Figure 1, the TextMonkey architecture features:
Initially, the input image is segmented into non-overlapping patches via the split module, each measuring 448x448 pixels. These patches are further divided into smaller 14x14 pixel patches, where each patch is treated as a token.
Enhancing cross-window relations. TextMonkey adopts Shfited Window Attention to successfully incorporate crosswindow connectivity while expanding the input resolutions. Besides, TextMonkey introduces zero initialization in the Shifted Window Attention mechanism, enabling the model to avoid drastic modifications to early training.
Token Resampler is utilized to compress the length of the tokens, thereby reducing redundancy in the language space. These processed features, together with the input question, are then analyzed by a LLM to generate the desired answer.
Performance
Since TextMonkey hasn't published its inference method yet, we will examine its capabilities through the experiments described in their paper. Our main focus is on its PDF parsing ability. That is, the ability to convert pdfs and images into structured or semi-structured data.
As depicted in the left portion of Figure 2, TextMonkey accurately locates and identifies text in both scene and document images.
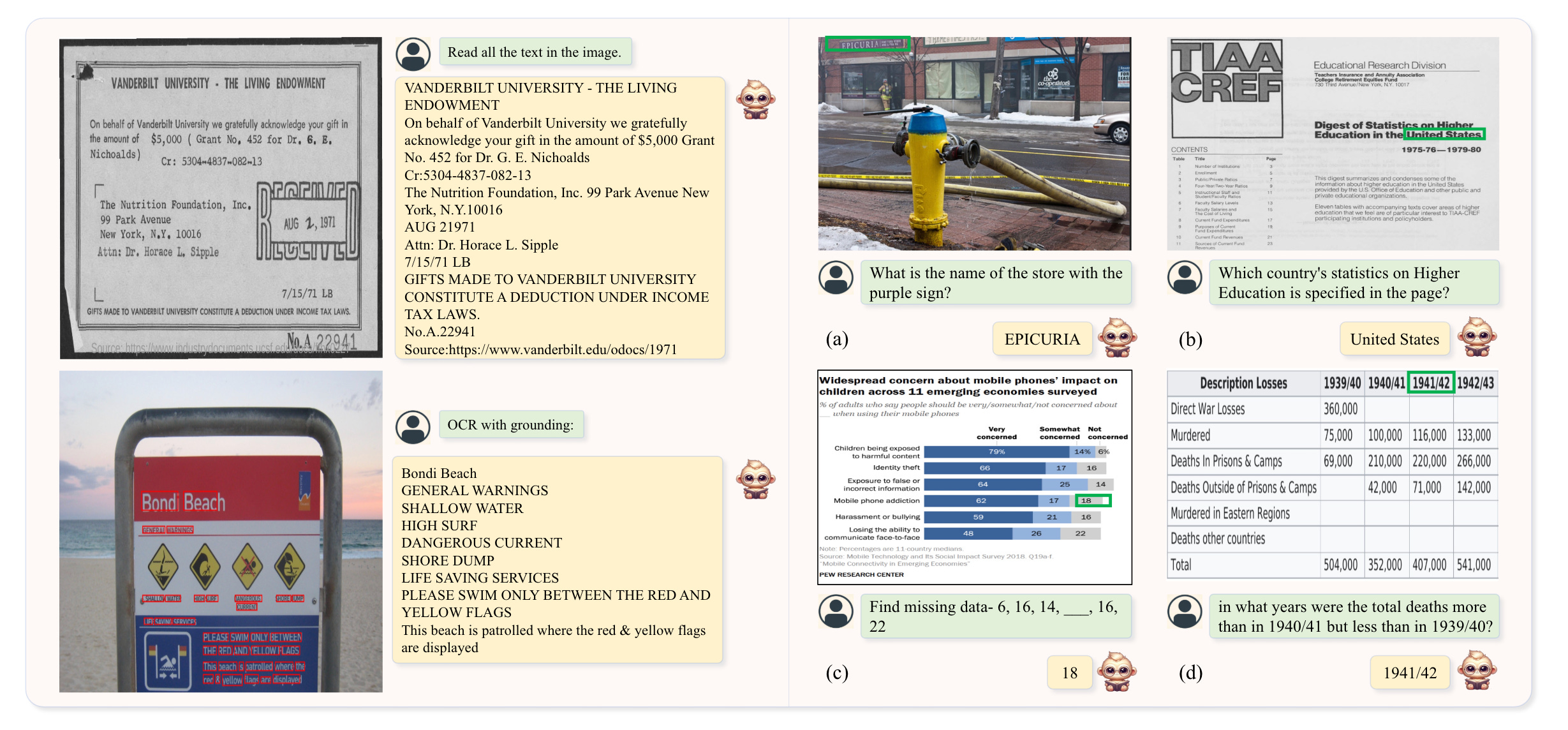
In addition, the ability to parse tables and charts is also crucial. TextMonkey has also conducted relevant tests, as shown in Figure 3.
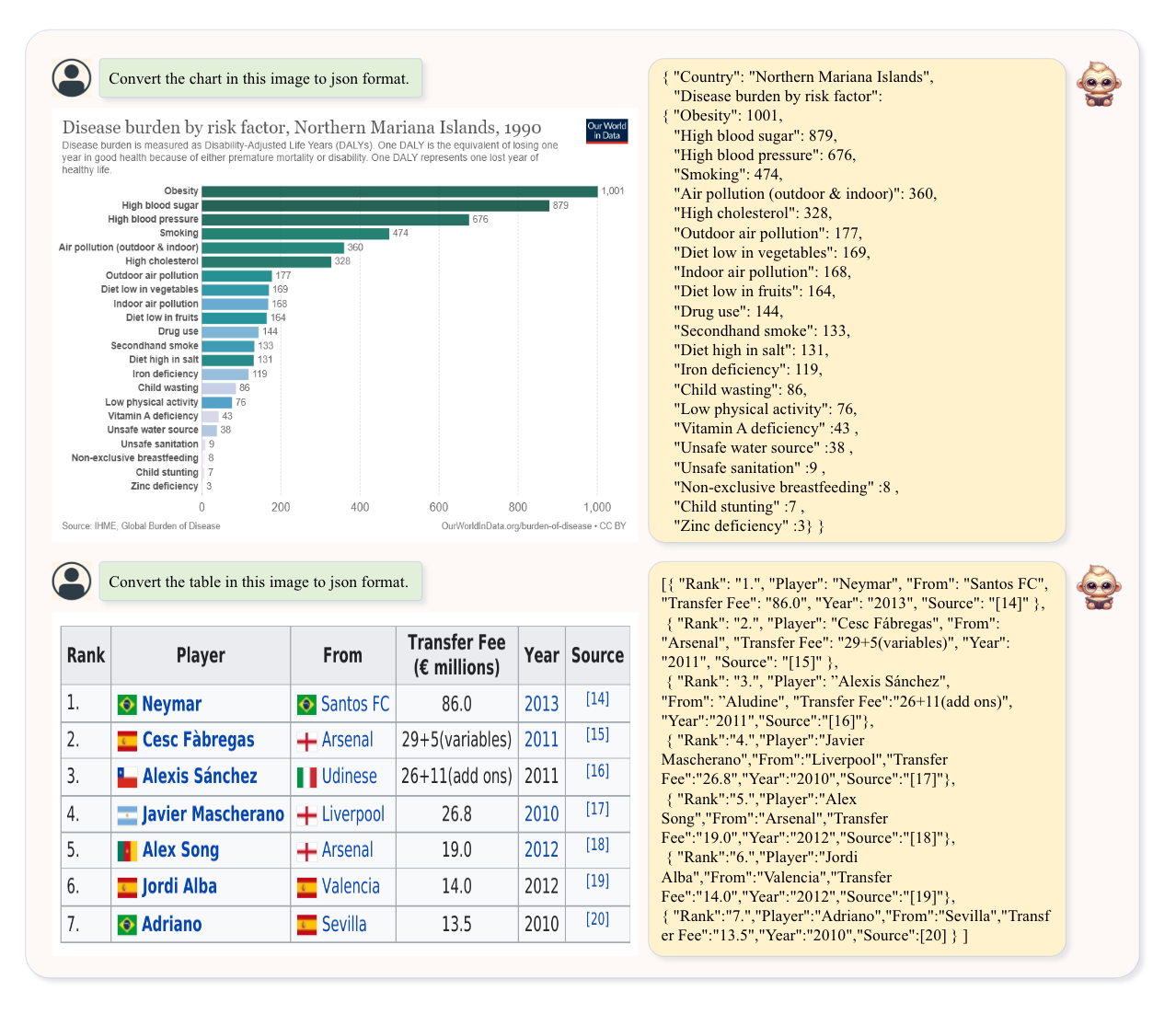
As shown in Figure 3, TextMonkey can convert charts and tables into JSON format, showcasing its potential for use in downstream applications.
Conclusion
TextMonkey is a fairly new, OCR-free, large multimodal model for understanding documents.
The paper includes comparative experiments that highlight TextMonkey's advantages.
Looking forward to TextMonkey publishing more complete code for testing.